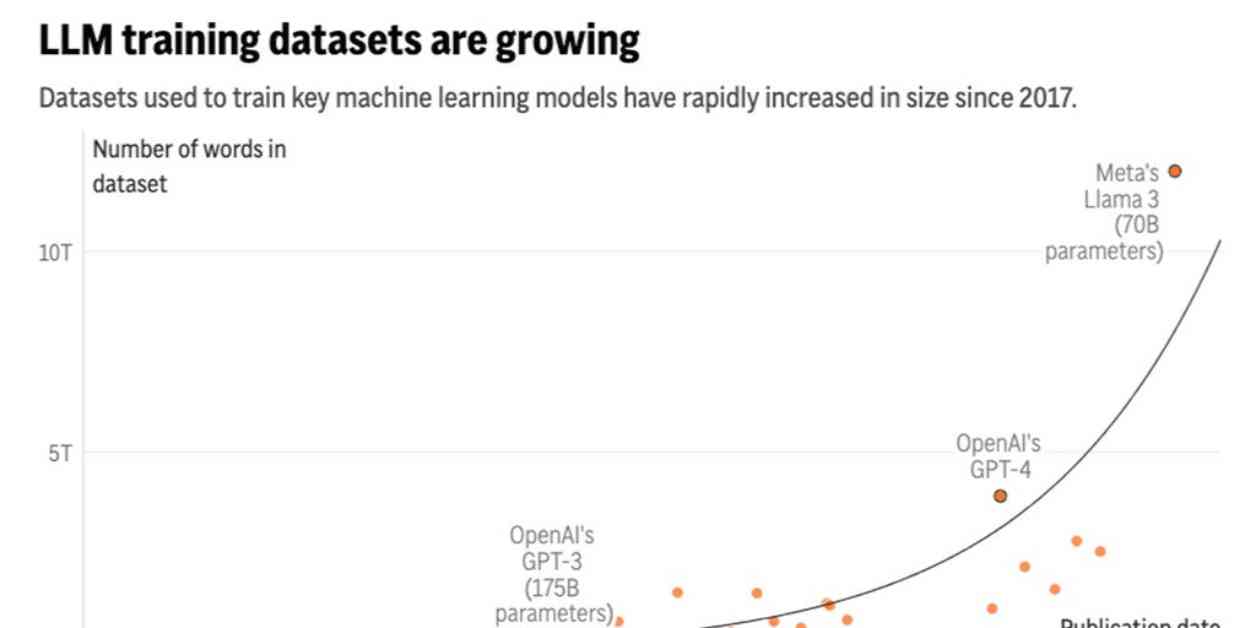
Artificial intelligence systems, such as ChatGPT, are soon expected to run out of human-generated text data that they need to continue improving. This issue has been highlighted in a recent study conducted by research group Epoch AI, which predicts that by the late 2020s or early 2030s, tech companies will deplete the publicly available training data required for AI language models.
As the supply of public data diminishes, developers are faced with the challenge of finding alternative sources to feed the language models. Some potential solutions include utilizing private data sources like emails or text messages and creating “synthetic data” through other AI models. In addition to these efforts, there is a growing focus on developing more specialized training models tailored to specific tasks.
Currently, companies like OpenAI and Google are actively seeking high-quality data sources to train their AI models, often entering into agreements to access information from platforms like Reddit and news media outlets. However, the long-term sustainability of AI development is in question, as the availability of new content like blogs and social media posts may not be sufficient to support the growth of AI models.
The study conducted by Epoch AI suggests that the amount of text data fed into AI language models has been increasing rapidly, alongside advancements in computing power. However, concerns have been raised about the potential limitations of relying solely on larger models for AI advancements. Researchers emphasize the importance of developing more specialized AI systems to avoid issues like “model collapse,” which can occur when generative AI systems are trained on their own outputs.
While the depletion of human-generated text data poses a significant challenge for AI developers, there are ongoing discussions about how to address this issue. Some organizations, like the Wikimedia Foundation, which oversees Wikipedia, are considering the implications of AI training on human-created data. While certain platforms have restricted access to their data, others, like Wikipedia, have maintained more open policies to encourage continued contributions from users.
Looking ahead, companies like OpenAI are exploring alternative methods, such as generating synthetic data, to train their AI models. However, concerns remain about the efficacy of relying solely on synthetic data for model training. As the field of AI continues to evolve, balancing the need for high-quality data with ethical considerations and technical advancements will be crucial for the future development of AI systems.


















