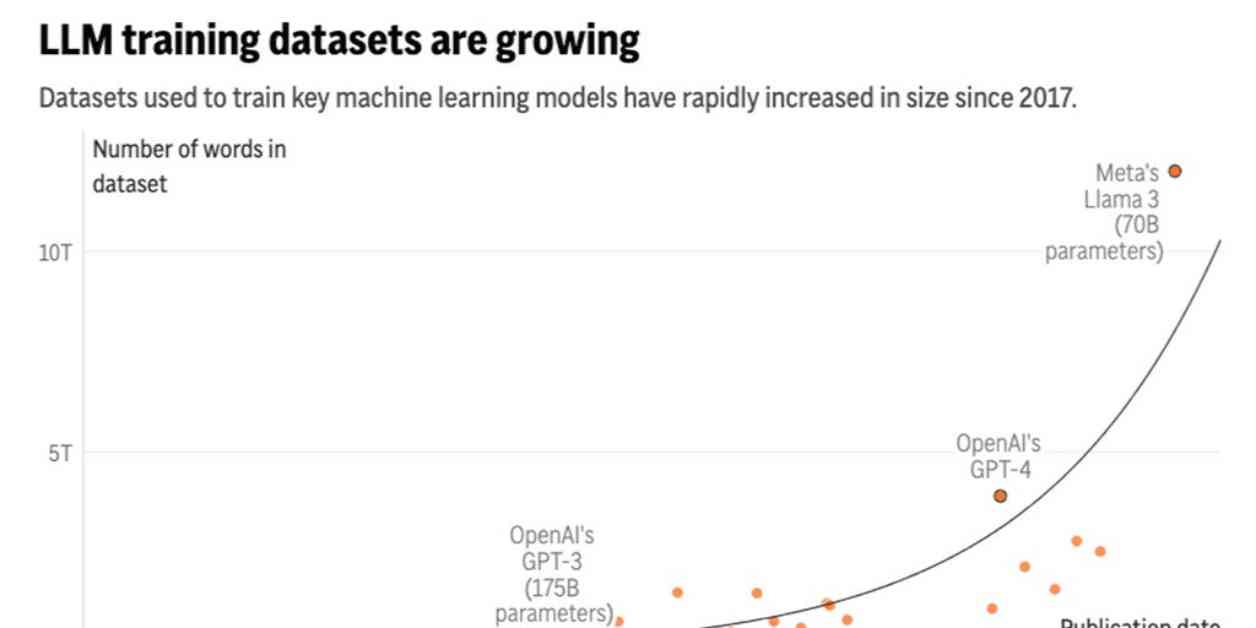
A new study by research group Epoch AI suggests that tech companies will run out of publicly available training data for AI language models between 2026 and 2032. Once this happens, developers will need to find new sources of data, such as private information like emails or text messages, or resorting to synthetic data created by other AI models. The study compares this situation to a “gold rush” that depletes finite resources, potentially hindering the progress of AI development.
In the short term, companies like OpenAI and Google are scrambling to secure high-quality data sources to train their AI models. However, in the long run, there may not be enough new data like blogs, news articles, and social media content to sustain AI development. This could lead to the use of private data sources or less reliable synthetic data, which may impact the efficiency and scalability of AI models.
The study highlights the importance of continuously feeding AI models with human-generated content to keep improving their performance. However, researchers are exploring alternative methods to enhance AI systems, such as building specialized models for specific tasks. Concerns about overtraining AI systems on the same data sources and the potential for biases and errors are also being raised.
While some organizations are restricting access to their data for AI training, platforms like Wikipedia are more open to AI companies using their content. Maintaining access to high-quality human-generated content is crucial for the development of AI models, even as concerns about the proliferation of low-quality automated content grow.
As companies like OpenAI focus on training the next generation of AI models, there is a debate about the reliance on synthetic data versus human-generated content. While synthetic data can be useful, there are concerns about its quality and efficiency compared to real human data. Balancing these factors will be essential for the future of AI development.
Overall, the study underscores the need for sustainable sources of data for training AI models to ensure continued progress in the field. Finding the right balance between human-generated content, synthetic data, and specialized models will be key to overcoming the potential data limitations facing AI language models in the coming years.


















